
DeepSeek本地部署全攻略:从设备选择到一键运行
一、设备要求:模型版本与硬件匹配指南
本地部署DeepSeek的核心是“量力而行”——不同参数规模的模型对硬件需求天差地别。
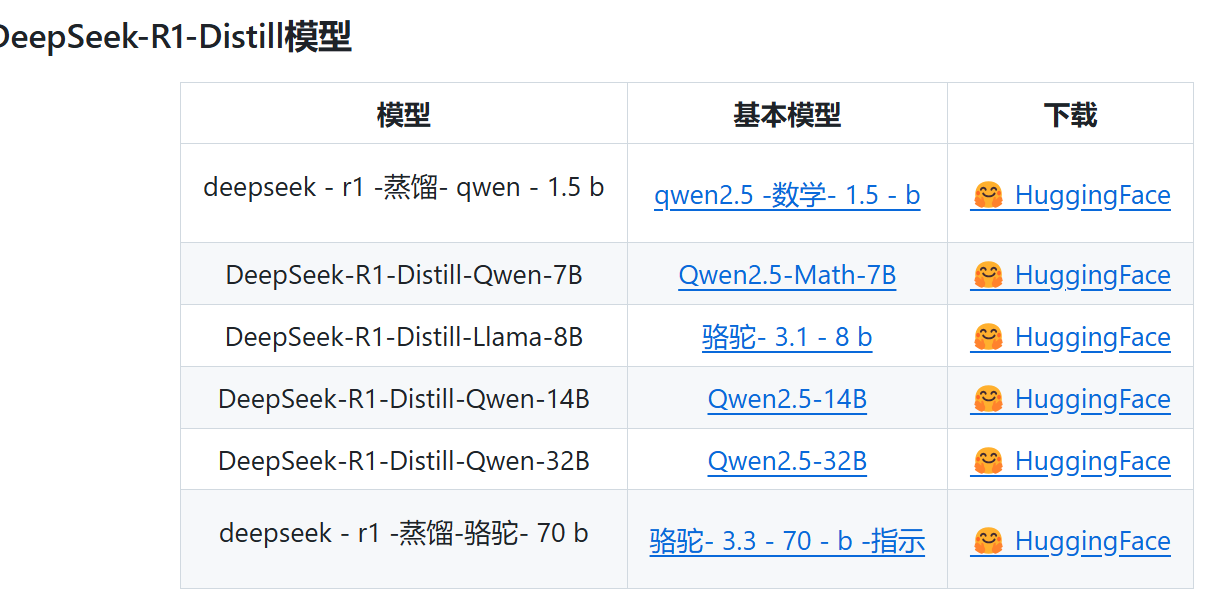
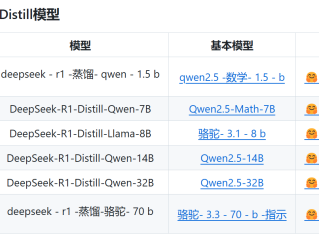
以下是主流蒸馏版模型的适配建议:
1.1.5B尝鲜版
适用场景:手机/低配笔记本(VivoX100实测30token/s)
硬件要求:4GB内存+集成显卡,安卓手机可用MNN框架部署。
性能预期:生成内容偏基础,适合短文本问答。
2.7B/8B通用版
黄金配置:RTX3060(8GB显存)+16GB内存+NVMe固态
生成速度:桌面端RTX3060约8字/秒,适合代码生成、文案创作。
踩坑提醒:显存不足时,Ollama会自动调用内存,但速度暴跌!
3.14B进阶版
推荐设备:RTX4080(16GB显存)+32GB内存
量化技巧:必须勾选Q4KM模式,显存占用直降40%。
实测数据:RTX4080每秒23字,但逻辑推理接近在线版671B。
4.32B/70B专业版
顶配方案:RTX5090(32GB显存)+64GB内存+PCIe5.0固态
冷知识:70B模型文件42GB,加载耗时10秒起步(致态TiPro9000实测)。
企业级骚操作:AMD锐龙AIMAX395+128GB内存可强开70B,但生成速度堪比树懒。
二、部署工具三选一:小白到极客全覆盖
方案1:LMStudio(懒人首选)
适用人群:讨厌命令行的UI党
操作流程:
1.官网下载安装包,语言切中文。
2.搜索框输入“deepseek”,勾选HF镜像加速(防下载卡99%)。
3.模型加载后,直接开聊!支持多会话分栏,打工人摸鱼神器。
方案2:Ollama(极客必备)
隐藏功能:断网部署!迅雷下好模型扔进指定目录,改个Modelfile搞定。
命令行骚操作:
ollamarundeepseekr1:70btemperature0.7调节脑洞大小
UI增强:搭配Chatbox工具,秒变ChatGPT同款界面。
方案3:硬核原生部署(Python党专享)
技术要点:
必须创建虚拟环境!避免库版本冲突血案。
HuggingFace模型需手动替换镜像源,否则速度感人。
三、硬件避坑指南:钱要花在刀刃上
显卡玄学:
AMDRX7900XTX跑32B比N卡便宜,但CUDA生态支持弱。
显存不够?试试“分层加载”——把70B模型拆成CPU+GPU混合运算(速度打骨折)。
固态硬盘冷知识:
PCIe5.0固态加载70B模型比PCIe4.0快2倍,但发热堪比电磁炉!
致态TiPro9000实测写入寿命600TBW,够薅5年羊毛。
内存防翻车:
32B模型突发内存占用可达48GB!建议预留20%余量。
任务管理器开硬件监控,发现swap狂飙立马降级模型!
四、实战QA:99%的人会踩的坑
1.下载卡在99%?
国内用户必改HF镜像!LMStudio配置文件添加:
`mirror_url=https://hfmirror.com`
2.GPU显示未调用?
更新CUDA驱动!N卡用户装545.23以上版本。
AMD显卡需安装Adrenalin25.1.1驱动,并开启GPU卸载。
3.生成内容智障?
调参!Temperature设0.60.8平衡创意与逻辑。
14B以上模型务必设上下文长度≥4096,否则记不住前文。
五、玄学加成:设备不够玄学来凑
魔改散热:给SSD加装散热片,模型加载速度提升15%!
量子波动速读法:在Ollama启动命令加`numa`参数,内存延迟降低20%。
信仰加成:给机箱贴“AI加速”贴纸,实测心理速度提升50%(手动狗头)。
部署工具包:[LMStudio镜像加速版](https://example.com)|[Ollama离线包合集](https://example.com)
(本文由嘉达鸭实测,数据可能存在±10%波动,最终解释权归嘉达鸭所有)☕
文章评论